




Scalable Web Scraping System
for Restaurants' Menu
Data Integration across USA

PROJECT AT A GLANCE
The project aimed to develop a highly scalable and fault-tolerant system to scrape and merge menu data from various fast-food chains across thousands of locations. The goal was to create a seamless pipeline for extracting, processing, and visualizing data efficiently.
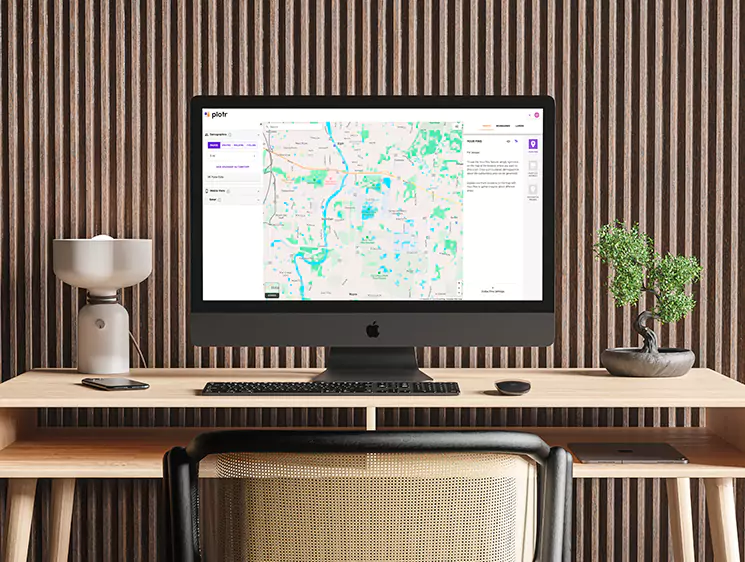
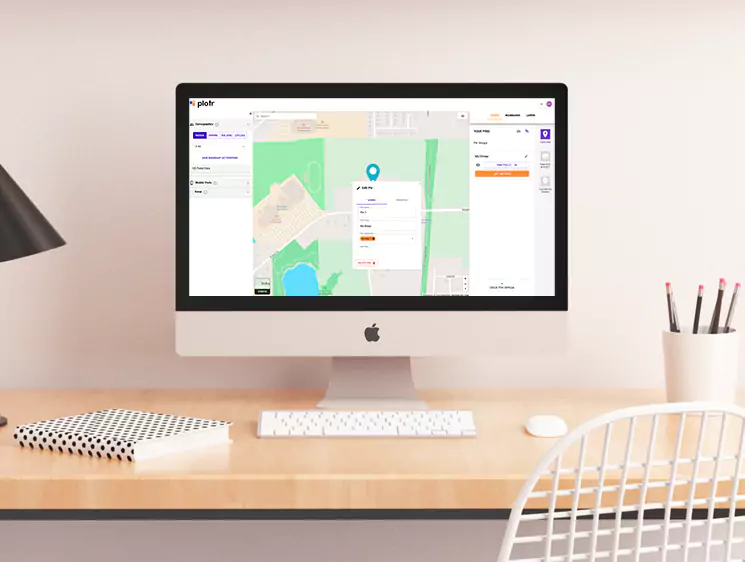
CHALLANGES
- Handling large-scale scraping operations across multiple locations.
- Managing diverse data formats from different fast-food chains.
- Ensuring fault tolerance and scalability for reliable performance.
- Reducing execution time from days to hours for each parser.
SOLUTION ARCHITECTURE TECHNOLOGY USED:
- AWS EventBridge & Step Functions: For orchestrating and scheduling web scraping tasks.
- AWS Lambda: To enable distributed processing, allowing tasks to run in parallel and scale automatically.
- AWS Glue: For cleaning, transforming, and merging scraped data.
- Snowflake: As the data warehouse to store processed data and generate visualizations.
IMPLEMENTATION DETAILS
Scalable Data Collection:
- Built parsers for multiple fast-food chains to extract menu data by location.
- Leveraged AWS Lambda to enable parallel scraping, reducing task execution time significantly.
Data Processing & Transformation:
- Utilized AWS Glue for processing raw data into a unified schema.
- Addressed discrepancies in formats across data sources to ensure consistency.
Scheduling & Automation:
- Configured AWS EventBridge and Step Functions to automate scraping schedules, ensuring up-to-date data
Data Export & Visualization:
- Exported processed data to Snowflake for storage.
- Enabled visualization capabilities for actionable insights and reporting
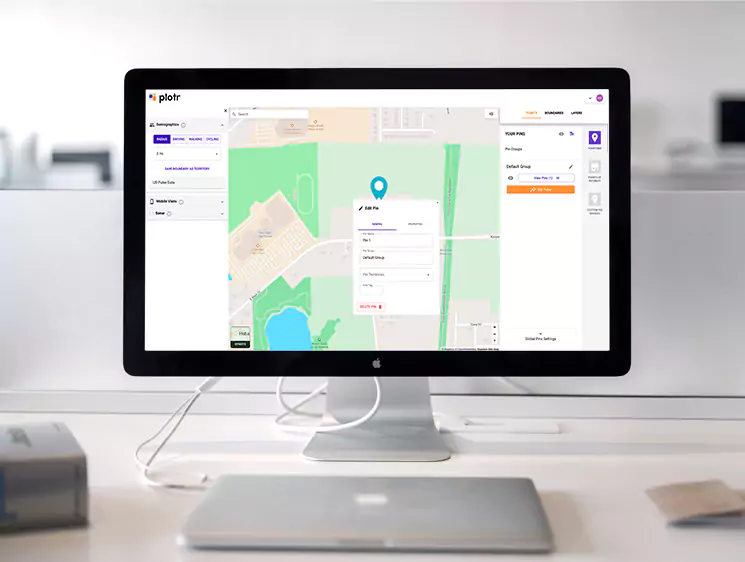
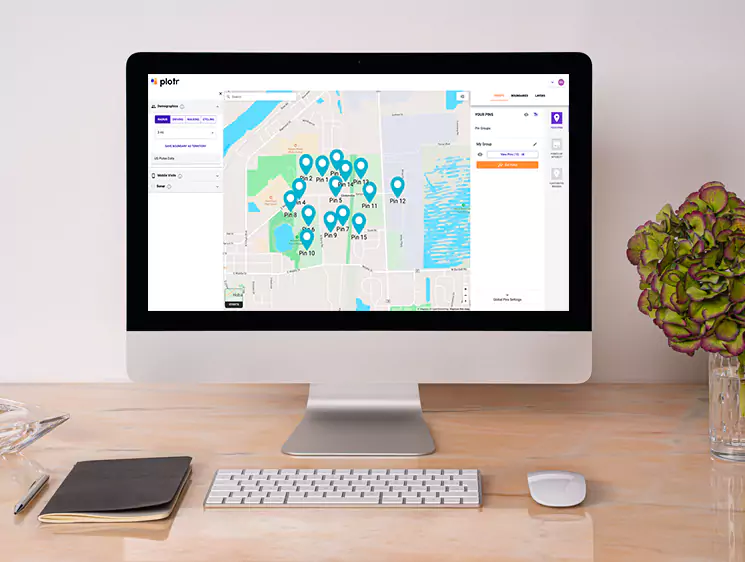
OPIMIZATION
Redesigned parsers and introduced parallelism to reduce runtime from days to hours.
RESULTS
- Achieved a 90% reduction in execution time for data scraping tasks.
- Delivered a fault-tolerant and scalable system capable of processing large-scale data seamlessly.
- Enabled real-time visualization of menu data in Snowflake for business insights.
- Improved overall system reliability and maintainability through AWS native services.
CONCLUSION
This project successfully demonstrated the integration of serverless computing, distributed processing, and advanced data warehousing to create a robust web scraping and data visualization pipeline. The optimizations and automation significantly enhanced data availability and decision-making capabilities.