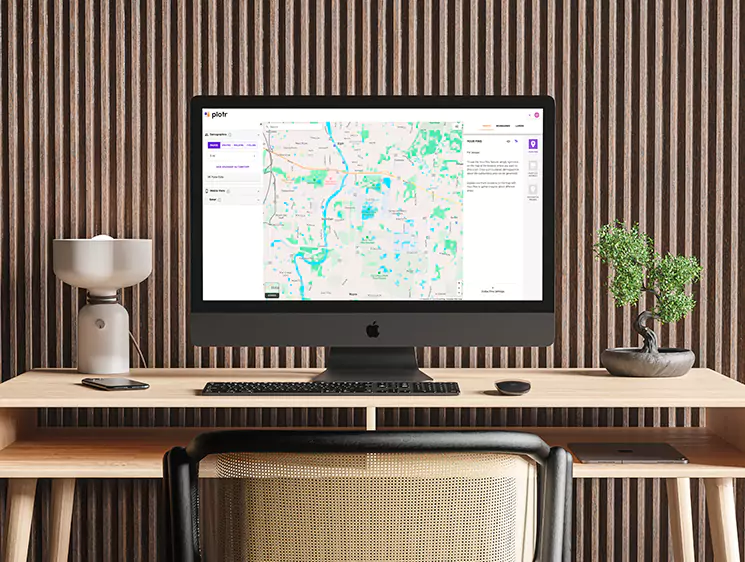
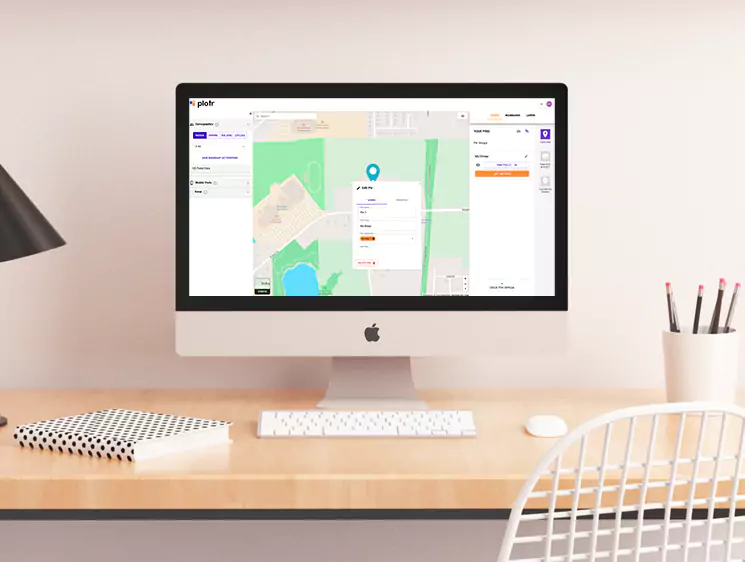
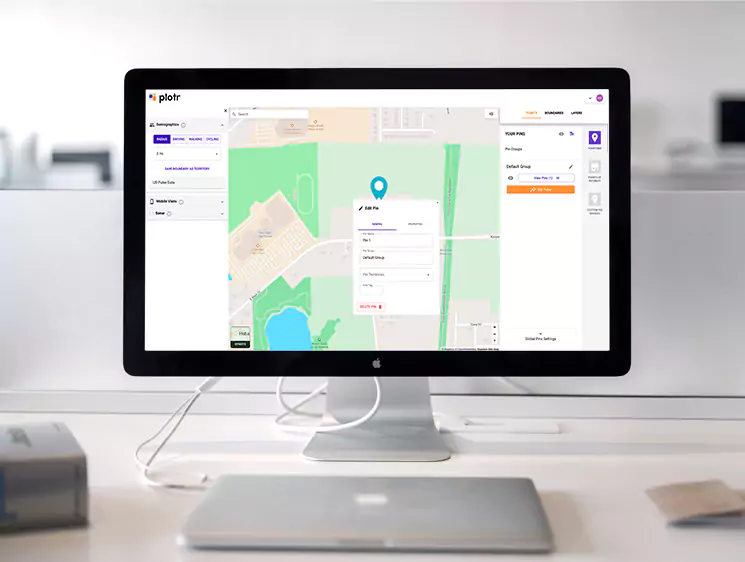
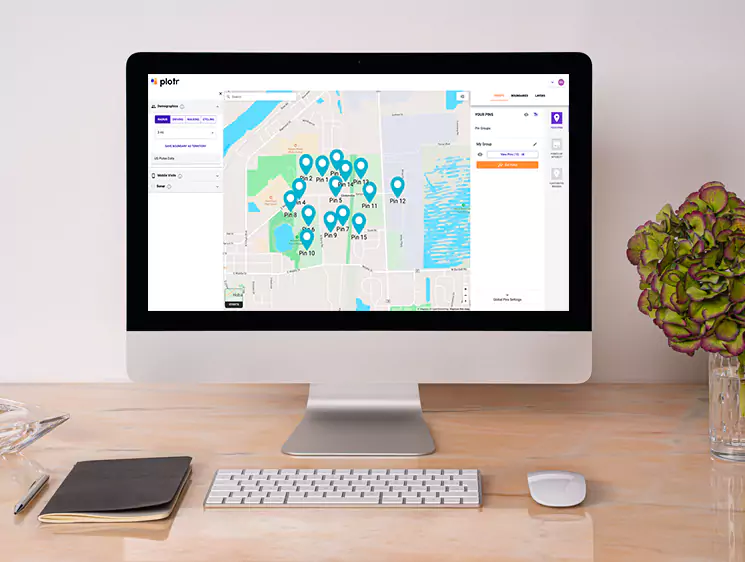
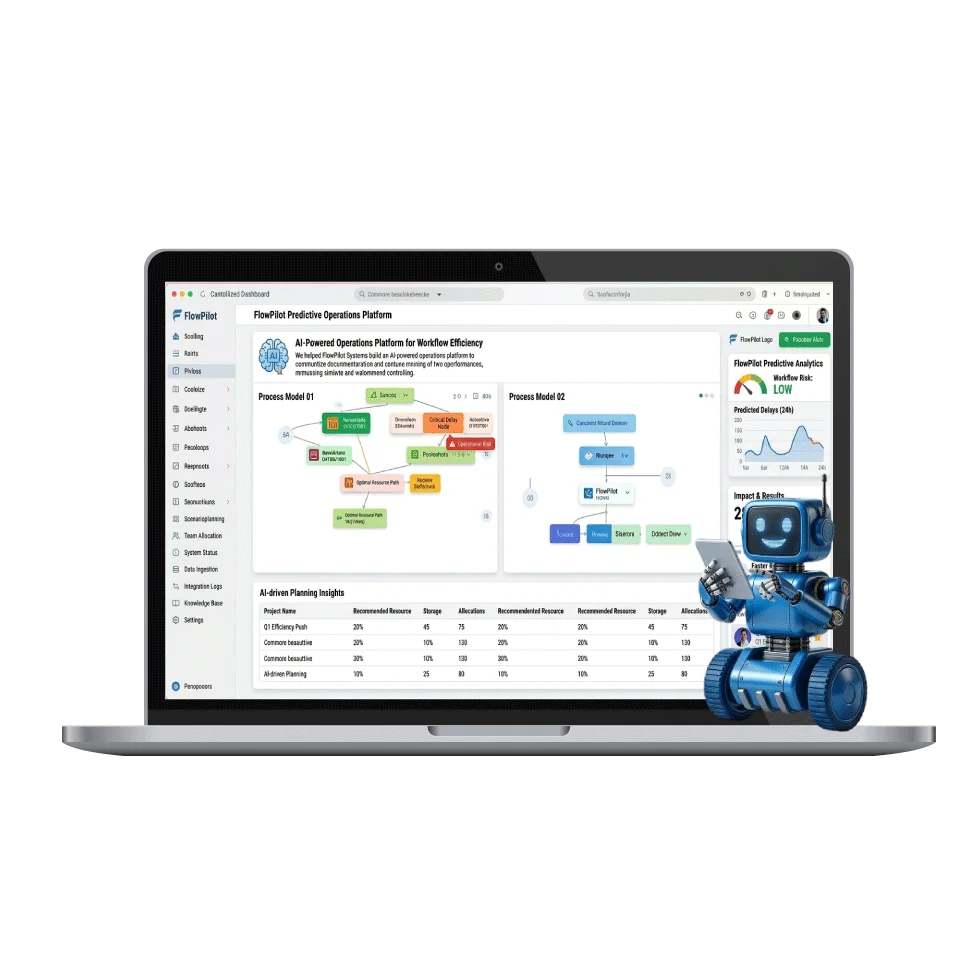
This project successfully demonstrated the integration of serverless computing, distributed processing, and advanced data warehousing to create a robust web scraping and data visualization pipeline. The optimizations and automation significantly enhanced data availability and decision-making capabilities.